Ethnographic Data Science: New Approaches to Comparative Research
Ethnographic Data Science: New Approaches to Comparative Research
Michael Fischer, Sridhar Ravula, Francine Barone, Human Relations Area Files, Yale University
Abstract: We discuss issues arising from applying natural language processing and data science methods to assist search and analysis of the largest online collection of ethnography, curated by the Human Relations Area Files (HRAF) at Yale University. In particular, we examine how comparative research might be better enabled and pitfalls avoided, and how eHRAF, and other online resources, can assume some level of interoperability so that research and practitioner communities can combine and utilise online data tools from different sources. iKLEWS (Infrastructure for Knowledge Linkages from Ethnography of World Societies) is a HRAF project funded by the US National Science Foundation. iKLEWS is developing semantic infrastructure and associated computer services for a growing textual database of ethnography (eHRAF World Cultures), presently with roughly 750,000 pages from 6,500 ethnographic documents covering 360 world societies over time. The basic goal is to greatly expand the value of eHRAF World Cultures to students and researchers who seek to understand the range of possibilities for human understanding, knowledge, belief and behaviour, including research for real-world problems we face today, such as: climate change; violence; disasters; epidemics; hunger; and war. Understanding how and why cultures vary in the range of possible outcomes in similar circumstances is critical to improving policy, applied science, and basic scientific understandings of the human condition in an increasingly globalised world. Moreover, seeing how others have addressed issues in the recent past can help us find solutions we might not find otherwise.
Introduction
iKLEWS (Infrastructure for Knowledge Linkages from Ethnography of World Societies) is a Human Relations Area Files (HRAF) project underwritten by the National Science Foundation Human Networks and Data Science programme. iKLEWS is creating semantic infrastructure and ethnographic research services for a growing textual database (eHRAF World Cultures), presently with roughly 800,000 pages from 7,000 ethnographic documents covering 361 world societies, each at several time points in the ethnographic present.
The basic goal is to greatly expand the value of eHRAF World Cultures to users who seek to understand the range of possibilities for human understanding, knowledge, belief and behaviour, whether to address work in anthropological theory, exploring the relationship between human evolution and human behaviour, or informing real-world problems we face today, such as: climate change; violence; disasters; epidemics; hunger; and war. Understanding how and why cultures vary in the range of possible outcomes in a range of circumstances is critical to improving policy, applied science, and basic scientific understandings of the human condition. Seeing how others have addressed issues can help us find solutions we might not find otherwise. This is extremely valuable in understanding an increasingly globalised world.
eHRAF World Cultures: Ethnography
Since its inception in 1949 (or 1929 for the ancestral files) the HRAF collection of ethnography has included manually applied topical metadata for each entry in each document. These entries roughly correspond to paragraphs, but may include images, figures, lists, tables, bibliographic entries, footnotes and endnotes. We refer to these entries as Search and Retrieval Elements, or SRE. Each SRE in each ethnographic work is classified by a professional anthropologist, who assigns one or more of 790 classificatory terms drawn from HRAF extensions of the Outline of Cultural Materials (OCM) (Murdock 1937-1982; see Ford 1971) to each SRE. A given instance of a classificatory term is an OCM code. The OCM thesaurus presently takes the form of a classificatory tree, nominally with three levels of major or minor topics, with some asymmetry.
Improving eHRAF WC:e
Although the current web version of eHRAF World Cultures is very fast at retrieving relevant ethnography, fundamentally it uses the same method as HRAF’s original paper files in 1949, just very much faster and more convenient. There are no aids to analysing the material once found; the user has to read the results of their search and apply their own methods. This project aims to fill this gap so that modern methods of working with text are applied through an extensible framework that deploys tools for analysis as well as greatly improving search capability. These tools will initially be available through a services framework, with interfaces for researchers ranging from beginner to advanced, accessible through web apps or Jupyter notebooks, either those that we supply, or following API guidelines for our services framework, constructed by the researcher. Over time these capabilities will be added to the eHRAF web application, usually in a more specialised or restricted form.
Data Science Methods
New semantic and data mining infrastructure developed by this project will assist in determining universal and cross-cultural aspects of a wide range of user selected topics, such as social emotion and empathy, economics, politics, use of space and time, morality, or music and songs, to use examples that have been investigated using prototypic tools preceding this project. Some of the methods used can be applied in areas as far afield as AI and robotics, such as forming a basis for a bridge between rather opaque (sometimes denoted as ‘dark’ ) deep learning outcomes and more transparent logic driven narratives, making AI solutions more human, and more useful through a greater capacity to generalise results. We are applying pattern extraction and linguistic analysis through deep learning, NLP and other tools to define a flexible logical framework for the contents of the documents. The goal is to apply these results as new metadata and infrastructure based on the outcomes of these procedures so that researchers can operate in real time and we can scale up using less processor intensive algorithms than most ML and NLP methods require.
All of the methods we are using employ machine learning in some form. Machine learning (ML) emphasises the notion that while we are employing algorithms to identify regularities in the text (patterns), the algorithm is responsible for identifying these regularities, rather than the researcher, who mainly assesses the outcomes of machine learning. For most of the history of computer-assisted text analysis, algorithms were used to restructure the text (counting words, indexing words, finding phrases), but it was pretty much the researcher that identified patterns based on the restructured text, although they might have a lot of algorithm-driven tools to for doing so.
Machine Learning
Although research on inductive learning algorithms began in the 1950s, it was not the 1980s that effective inductive algorithms became available that could generate inductive classifications of relatively complex data, such as ID3, which could infer decision trees for classifying outcomes against attributes (Quinlin 1986), though these data were usually discrete in nature; a list of temperatures, barometric readings and weather observations could be used to 'predict' weather, for example. But this could be applied to textual analysis if the researcher could specify usable observations drawn from the text, such as the presence of one of a cluster of words on a page. By the early 1990s the number of such algorithms was sufficient that toolkits became available, such as Weka in 1993. By 2000 a large number of pattern extraction algorithms had been implemented in many computer languages, and were present in widespread statistical packages, such as SPSS, SAS and R. These included sophisticated ML algorithms such as neural networks (NN) of various flavours. Unlike most the pattern extraction algorithms, whose operation in principle could be analysed and understood procedurally and structurally, NNs produce results with very little insight into how the input information is processed to produce outcomes, or even how the input information is represented in a given NN. This has resulted in many researchers classifying neural networks as 'opaque' ML, or even 'dark' ML. Both 'conventional' inductive, and even abductive, approaches and neural network approaches have continued development, largely driven by the massive increases in processor speed and complexity, memory and storage capacity, making 'Big Data' possible.
There are three basic methods used in machine learning: Supervised learning works with labeled input or output data and usually requires less training to achieve good results. Unsupervised learning classifies unlabelled data by identifying patterns and relationships from within the data set. Partially-supervised learning is applied to a small labeled data set sampled from a larger unlabelled data set, producing a model that can be applied to the full set otherwise unsupervised, for example by predicting labels for the unlabelled data.
There are four steps in building a machine learning model:
- Choose one or more algorithms to run on the training data.
- Identify and assemble a training data set that can address a given problem. This data can have inputs and outputs labeled or unlabelled, depending on the algorithm chosen. When labeled, the algorithm might best be suited to regression, decision trees, or instance-based solutions. If unlabelled, the algorithm might better employ clustering, association, or a neural network.
- Train the algorithm against either a sample of the data set, or possibly the entire set, to create a model that can classify data of this sort.
- Iteratively apply and improve the model.
Applications of Machine Learning
These processes are summarised in Figure 1. In the figure, Data is whatever you have on hand to analyse. In our case it is around 4 million entries that roughly correspond to paragraphs from some 7000 documents. Selection is a key step in processing data, a kind of 'proto' labelling. For example, in our case we might take all of the entries that correspond to one or more OCM codes, say Arranging a Marriage (584), and Termination of Marriage (586). Different algorithms require data in different forms, so we are likely to have to Preprocess and Transform the data in some manner. For a given algorithm, we may need to convert each entry into individual sentences, and we may need to modify certain words to direct the algorithm in the direction our goals require. For example, some researchers modify words by stemming them, removing plural markers, tense markers and possessives. Or they might use lemmatisation, picking a single form of word for all derivatives of that word. For some of our cases, we preprocess using a procedure called Named Entity Recognition, which replaces named individuals with the term 'person' (or 'male' or 'female'), organisations with 'org', specific numbers with 'cardinal', dates with 'date' etc. This seems to work well with ethnographic writing, because in ethnography there is little value in most cases to consider specific people, organisations, numbers or dates - this just generates noise when looking across many ethnographies covering many peoples. Many contexts do much better with a generic form of marking. Data Mining is application of the algorithm to identify patterns in the data. There are a wide range of different algorithms as discussed earlier. Interpretation/Evaluation is of course the crux of the process, as this is where researchers evaluate the value of the algorithm chosen to solving the problem they have set forth. For example, we could evaluate the effectiveness of the algorithm in differentiating SREs selected by OCM 584 from OCM 586. Eventually, Knowledge is acquired to direct future activity, which might be further research, or developing a policy for water conservation.
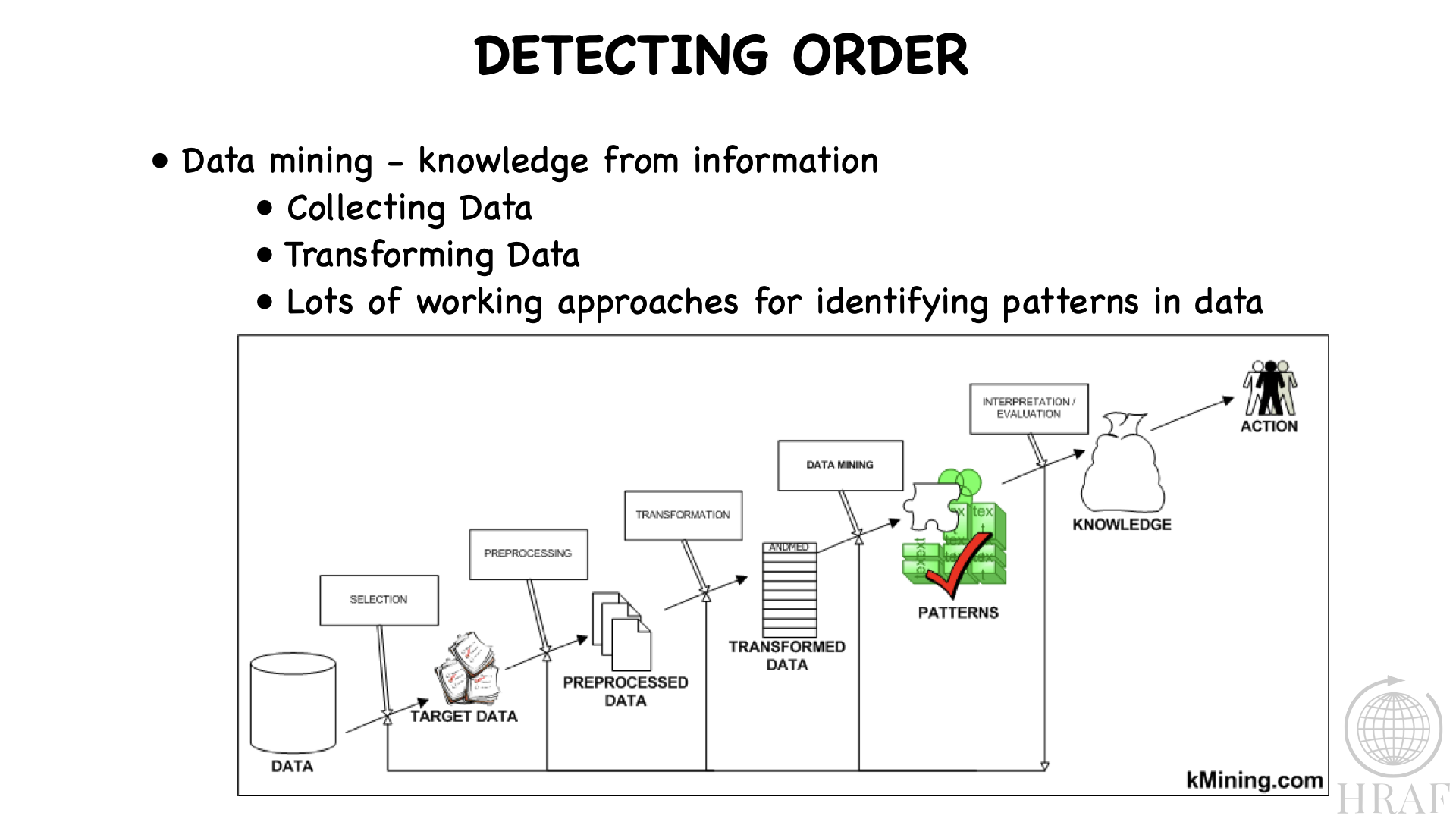 Figure 1. Detecting order.
Figure 1. Detecting order.
 Figure 2. Identifying significance: Goldilocks words.
Figure 2. Identifying significance: Goldilocks words.
Some examples of methods
Following are examples reflecting basic outcomes of two of the approaches we are using in the project. The first, Word2Vec is an example of machine learning using neural networks trained against the ethnographic data in eHRAF. Word2Vec will construct a word vector for any given word, with modifications based on other contextual terms supplied. The word vector is headed by the term selected, say Culture, as in Figure 3., which presents the 10 terms that behave the most like the term 'culture' within the overall text. Because it is based on neural networks, we can't look to see why it made these determinations. However, we can look at the members of the list, including many more than the 10 shown, to induce an explanation for the 'behaviour' of the vector. Also note the use of bigrams (e.g. world_view), which are frequently significant in ethnographic writing. These are included in the preprocessing stage.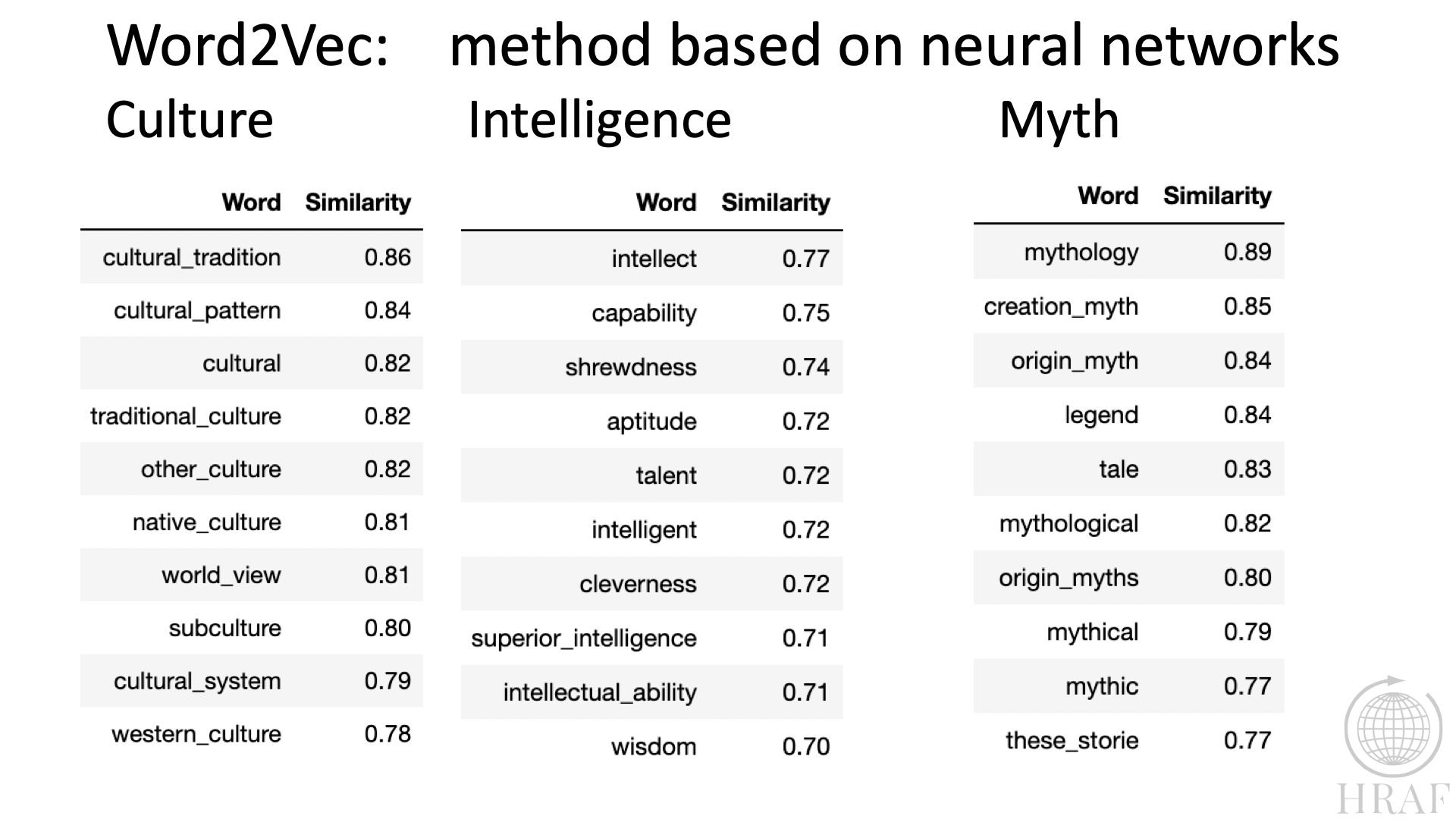 Figure 3. Word2Vec for three terms denoting important Anthropological concepts.
Figure 3. Word2Vec for three terms denoting important Anthropological concepts.
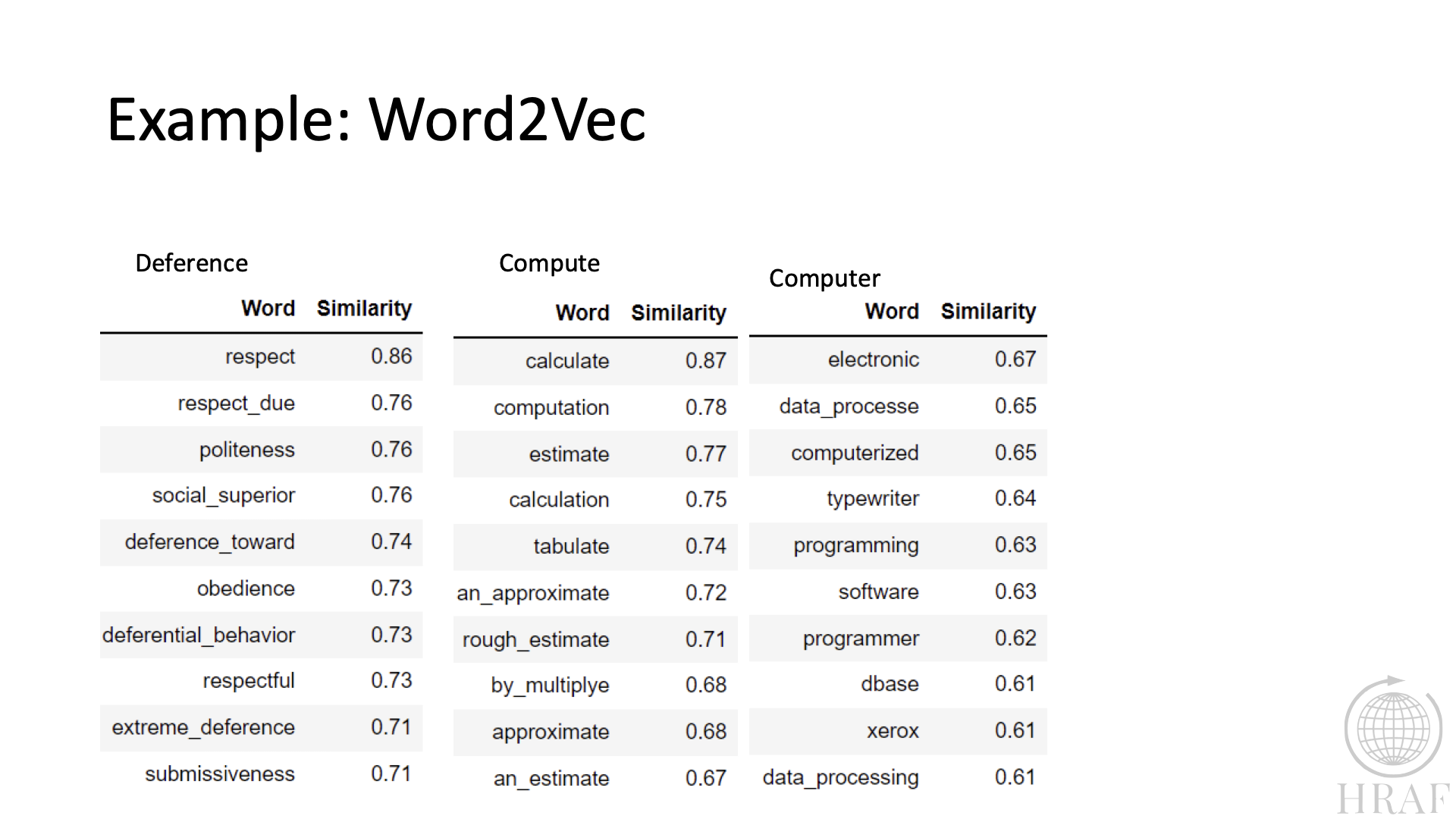 Figure 4. Word2Vec for three terms denoting less significant terms.
Figure 4. Word2Vec for three terms denoting less significant terms.
In Figures 5. and 6. Word2Vec is influenced by a term included to project the vector with respect to a modifying term corresponding to positive or negative sentiment, and passive and active sentiments. These substantially alter the vector composition.
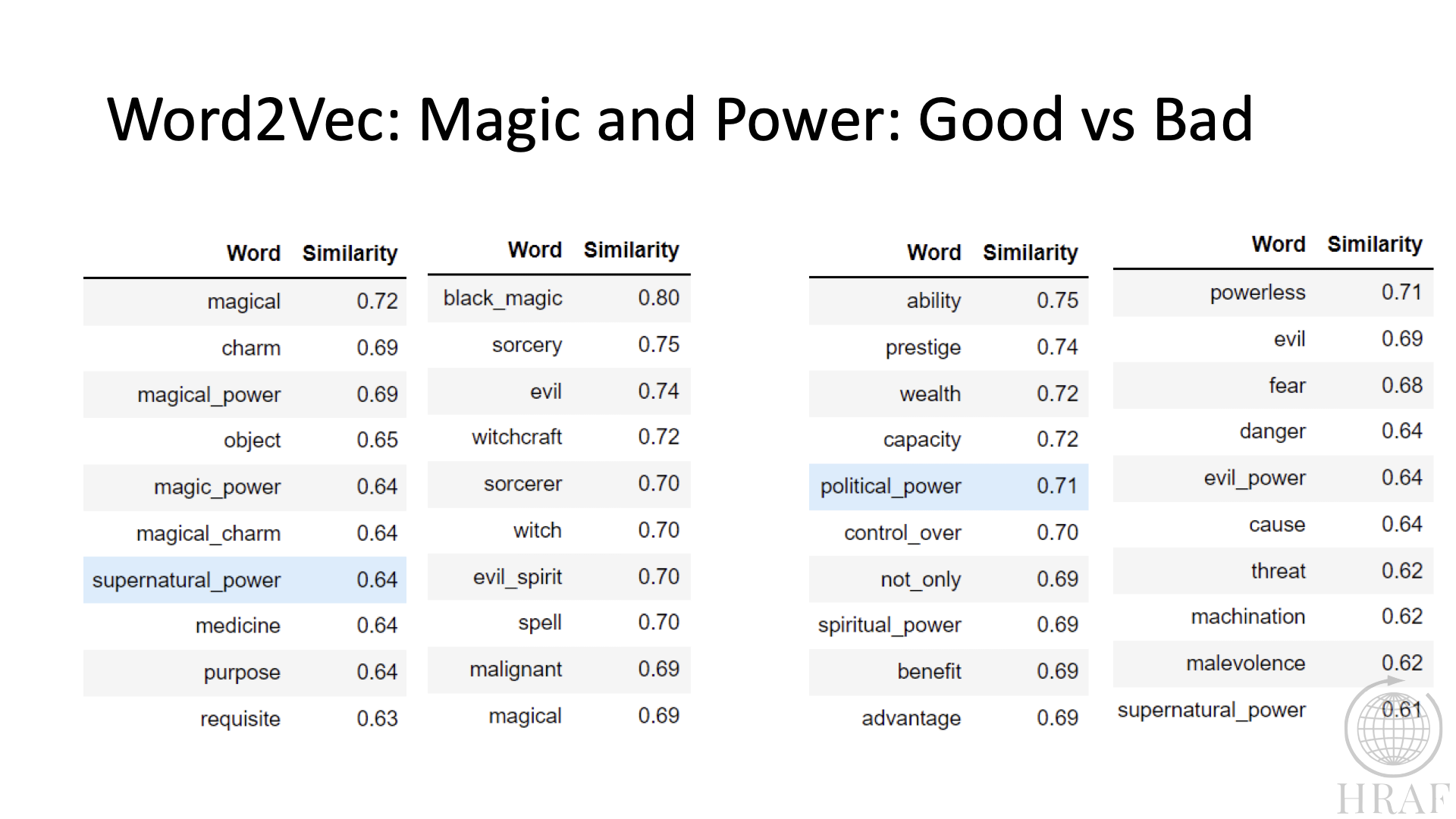 Figure 5. Word2Vec words rescaling based on Good vs Bad contexts.
Figure 5. Word2Vec words rescaling based on Good vs Bad contexts.
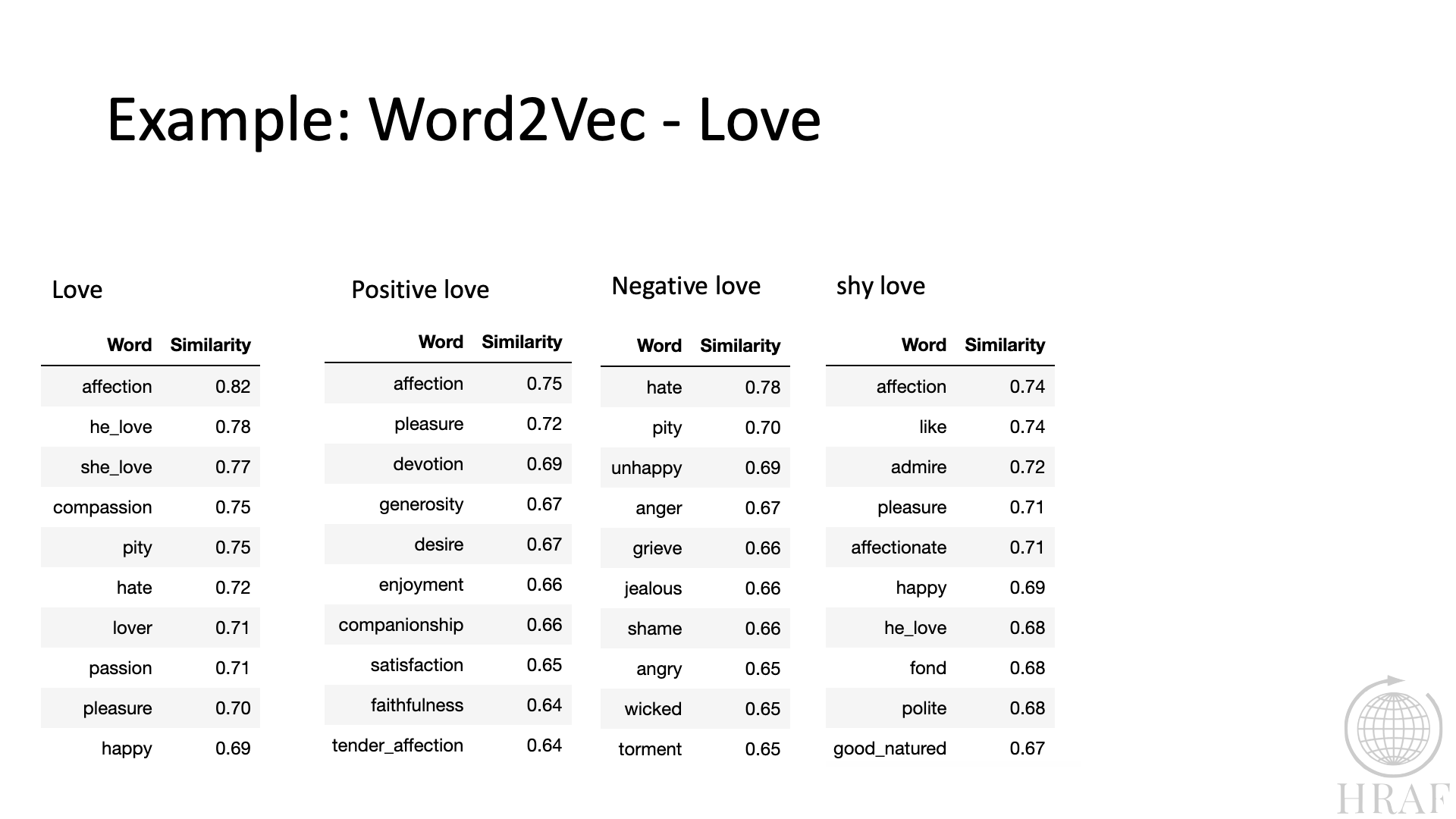 Figure 6. Word2Vec words rescaling based on Positive/Negative/Passive contexts.
Figure 6. Word2Vec words rescaling based on Positive/Negative/Passive contexts.
Word2Vec can be used in many ways, beyond the simple fascination of examining the vectors. For example, it can be used to broaden search terms, or as part of other algorithms assist in generating dynamic local ontologies. It can be useful in developing a more semantic account of the textual content, and in developing logics that have broad applicability throughout the text. Although the Word2Vec itself is inscrutable in not revealing how it chooses the terms, we can use the outcomes to induce logics that are effectively theories about the relationships between the terms in the vector, and are subject to examination and refinement.
Topic extraction and topic mapping are also important methods for the iKLEWS project. The basic idea underlying topic extraction is the identification of word clusters through induction that characterise a common theme. We are mainly using LDA, a common algorithm for topic extraction. Using LDA, topics are sadly not simple discrete labels. Rather a topic is a cluster of words. These words do not have all appear in a text segment to be applicable to the text. For example, Figure 7. illustrates that despite mainly consisting of numbers, it attracts the topic 'may rain water season dry rainfall_cardinal quantity loc date'. Figures 8. And 9. cover more typical anthropological material. LDA is sensitive to the context of a given fragment of the text. Also, one of our preprocessing steps is application of NER, which labelled all of these as cardinal numbers, and 'cardinal' is a component of the two topics that the SRE is assigned. One of our objectives is to develop ways to represent these topics to researchers so that they can make sense of these and use them interpretatively. Part of the solution will be based on associating topics with derived logical models so that we can create interactive means for researchers to navigate the text using the topics. We have so far applied some of this logic to preprocessing the text to improve the clarity of the topics generated, such as NER. Adding this step has had a major impact on the interpretability of the topics, not just because it simplifies the text by removing a lot of detail, but because ethnographies do not focus on specific individuals as analytic subjects beyond the actual narrative relating the informal. Specific people are used to illustrate ideas that are applicable to many people.
 Figure 7. Topics from SRE from sample drawn from OCM 130
Figure 7. Topics from SRE from sample drawn from OCM 130
 Figure 8. Topics from SRE from sample drawn from OCM 586
Figure 8. Topics from SRE from sample drawn from OCM 586
 Figure 9. Topics from SRE from sample drawn from OCM 585
Figure 9. Topics from SRE from sample drawn from OCM 585
Discussion
These methods and outcomes, with others, will result in improved relevance of search results though identifying new and finer grained topics in each SRE in addition to those associated with the OCM; establishing semantic representations of SREs in the texts with semantic links between SREs so that a researcher can follow topic trails more effectively; and provide tools for management, analysis, visualisation, and summarisation of results, user-initiated data mining and pattern identification, based largely on precomputed data. These will assist researchers identifying and testing hypotheses about the societies they investigate.
In the context of this session, Programming anthropology: coding and culture in the age of AI, while we have not attempted an ethnography of the methods we have used, or the processes of their application, we have been very mindful of how our choice of methods might influence or bias future research carried out on the infrastructure we are developing. We must consider the impact of these massive additions to eHRAF, particularly the impact on researchers, how and what they can research, and the bias we could be introducing to research outcomes.
One obvious problem with data science and NLP methods is that these are either based directly on statistical methods, and each thus is associated with a probability of error, often 10% or more, or are based on non-deterministic ‘deep learning’ through adaptations of ML, including neural networks, which are more or less opaque with respect to their internal operation - the algorithm is known, the details of operation are known, but the validity of outcomes can only be accessed through practice. Only the outcomes are explicable, and again, these imbue substantial margins of error in application, 10-20%, which is regarded as ‘good-enough’ by much of the ML community. Even if we also accept these results as good-enough, we have only made a limited gain, as we have a limited ability to relate the outcomes to the individual constituents that, combined with the algorithm, contribute to the outcomes.
This is not as limiting as it might seem at first consideration. The ignorance is, in principle, specific to demonstrating the detail of evolving relationships, and thus the inability to fully understand how a history of interactions leads from the original context to the outcomes of algorithmic application. But at the same time, the algorithm is available, the properties of constituents known, and knowledge of the underlying logic that motivates the algorithm and specified constituent properties is available. Armed with the latter elements, one gains an understanding of the process, if not an absolute understanding. Less than ideal, but not dissimilar to the limits of ethnological precision of an expert ethnographer. The limits of analytic processes, and the error rates associated with these, can be documented and applied to use.
From a developer’s, and an anthropologist’s, point of reference, it is important that we provide constant reference to these limitations, given the propensity of researchers to accept the outcomes of such procedures as definitive, or are over-suspicious. But just as imperative is the need to provide similar guidance for the content of the ethnographies themselves. Over time ethnological conceptions and perceptions have changed, been added or eliminated. Focal interests and themes change. Objectives change. Biases change. Early sources were often produced by missionaries, administrators, or tourists. Even then, eHRAF’s coverage of a society might range from the 16th century to the 21st century, covering a range of different perspectives from many different roles. This guidance does not take the form of specific guidance on specific documents, but rather of tools and procedures to assist in evaluating content against other ethnographic sources, and identifying critical assumptions in the text.
To achieve our objectives we are including methods adapted from Natural Language Processing (NLP), Machine Learning (ML), topic extraction and other areas of data science. The immediate goal is to add new data and metadata arising from this work to the current ethnographic collection at the SRE level. The new data and metadata is leveraged through a services framework which can be accessed by the eHRAF web application to expand search capabilities and add capabilities for analysis of results beyond simply reading returned results. Researchers can also access data and analytic processes more directly through a Jupyter notebook which can be run on the researcher’s computer directly, or using a web application such as Kaggle or Google’s Collaboratory.
So we will a) expand the metadata for the eHRAF database using NLP, ML and a range of more conventional textual analyses, b) expose the contents of the eHRAF database to data mining and analysis by researchers through an API, c) develop services that leverage the API to process results, and d) provide a range of approaches to leveraging the API to suit researchers with different levels of technical skill, including web applications, JupyterLab workflow templates, and direct API access.
By exposing data, metadata, computer assisted text analysis methods and data management tools, with guided means to leverage these through interactive web applications and JupyterLab templates together with interactive exemplars and training materials, we will expand capacity to advance secondary comparative, cross-cultural, and other ethnographic research and extend this capacity to a much wider constituency of researchers. These services will make practical the inclusion of cross-cultural analysis in research whose primary purpose is quite removed from this track, such as consideration of cross-cultural approaches to common or new problems.
References
- Ford, C. S. (1971). The Development of the Outline of Cultural Materials. Behavior Science Notes, 6(3), 173–185. https://doi.org/10.1177/106939717100600302
- Holmes, Geoffrey; Donkin, Andrew; Witten, Ian H. (1994). "Weka: A machine learning workbench". Proceedings of the Second Australia and New Zealand Conference on Intelligent Information Systems, Brisbane, Australia.
- Quinlan, J. R. 1986. Induction of Decision Trees. Machine Learning 1, 1 (Mar. 1986), 81–106.